previous post: [Into Emulators]
# Into Assemblers
Back in the previous post about the chippy project, I said I'd finish the emulator throughout the reading week and that I'd document it all in here. Well, that was a huge lie. Almost a month later the emulator isn't finished, and I didn't document any of the changes, nor will I be doing that in this post. I implemented 21 of the 35 opcodes, and while livecoding this project on [twitch], a viewer brought to my attention that maybe writing the ROMs I used to test chippy by hand, opcode by opcode, in a uint16_t array and writing that to a file wasn't the best way of doing things:
uint16_t rom[] = { 0x2216, 0x3168, 0x6030, 0x7001, 0x00E0,
0x3069, 0x1206, 0x8300, 0x833E, 0xC169,
0x121A, 0x6268, 0x00EE, 0x00E0, 0x00E0 };
And it definitely wasn't fun for the viewers either. The above program counts from 0x30 to 0x69, then copies the data over to another register and left-shifts it by one. It then places a random value in another register, all while doing some random useless operations for testing purposes. I'm still using that exact ROM to test chippy. But if you don't know chip-8 bytecode by heart, this means absolutely nothing to you.
So I started work on an assembler, called chasm, so I could write my programs in a semi-readable language and get usable chip-8 bytecode for my emulator / virtual machine to interpret.
## The Language
I'm not an assembler expert by any means. I know some ARM assembly due to my first-year computer architecture class in college, but that's pretty much it. So some of the assembly mnemonics might sound weird to people with more experience, but I just went with what made sense to me and/or sounded cool. So far we have:
CLEAR - disp_clear()
RETURN - return;
B NNN - goto NNN;
CALL NNN - *(0xNNN)()
IFE VX, #NN - if (Vx == NN)
IFNE VX, #NN - if (Vx != NN)
IFE VX, VY - if (Vx == Vy)
MOV VX, #NN - Vx = NN
MOV VX, VY - Vx = Vy
MOV I, NNN - I = NNN
ADD VX, #NN - Vx += NN
ADD VX, VY - Vx += Vy
ADD I, VX - I += Vx
OR VX, VY - Vx |= Vy
AND VX, VY - Vx &= Vy
XOR VX, VY - Vx ^= Vy
SUB VX, VY - Vx -= Vy
LLS VX - Vx >>= 1
SUS VX, VY - Vx = Vy - Vx
LRS VX - Vx <<= 1
IFNE VX, VY - if (Vx != Vy)
BA NNN - PC = V0 + NNN
RAND VX, #NN - Vx = rand() & NN
DRW VX, VY, #N - draw(Vx, Vy, N)
IKE VX - if (key() == Vx)
IKN VX - if (key() != Vx)
GDL VX - Vx = get_delay()
GTK VX - Vx = get_key()
SDL VX - delay_timer(Vx)
SSD VX - sound_timer(Vx)
SPR VX - I = sprite_addr[Vx]
BCD VX -
set_BCD(Vx)
*(I+0) = BCD(3);
*(I+1) = BCD(2);
*(I+2) = BCD(1);
DPR VX - reg_dump(Vx, &I)
LDR VX - reg_load(Vx, &I)
For context: VX, VY and I are registers (where I is comparable to the Link Register in ARM),
NN and N are constants (8-bit and 4-bit respectively),
and NNN is an address
Where on the left there's the assembler instruction and on the right there's the C pseudo-code of what that instruction does. It's definitely unwieldy, and I'll probably change some of the mnemonics during development, but it'll do for now.
## Tokenizing
I first started writing the tokenizer instruction_t tokenize(char *line). The instruction_t struct is simply an array of tokens and its size:
typedef struct {
int count;
token_t tokens[5];
} instruction_t;
Where token_t contains the kind of the token, its string representation, along with its line and its column in the source file (for printing errors):
typedef struct {
TokenType type;
char *data;
int line;
int col;
} token_t;
tokenize() used strtok() to get tokens from the line given to it as argument and compared their starting character with some key ones (like ; for comments, . for labels, V for registers, # for constants and 0 for addresses (0x for hex and 0b for binary).
Depending on the match (if there is one), the token's kind (type) and data get set. Then, the tokens that didn't match to anything in that big switch-case statement went on to a for loop that compared it to every mnemonic until it got a match, using the same index in the string array to get the TokenType value:
for(int i = 0; i < ARRAY_SIZE(instructions); i++){
tok = nulltok; //this is the default "empty" token
if(strcasecmp(data, instructions[i]) == 0){
tok.type = i;
tok.data = data;
break;
}
}
where instructions[] is an array of strings containing every mnemonic in the same order as the TokenType enum.
## Onto The Second Pass
This worked fairly well and got me perfectly categorized tokens after some fine-tuning. I thought I could write the entire assembler with a single pass like this, but I quickly ran into some problems with the labels: A non-existant label could still be referred to in an instruction (say, CALL .loop1) and I couldn't think of a way to overcome that with my humble single-pass architecture, so I had to add another layer.
I created a very rudimentary symbol table. It's nothing but a dynamic array of strings, with a few boilerplate functions to operate on said array. Each string in the array contains the label itself (.loop1) and its associated address, separated by a column: .loop1:0x3FA. A parse() function iterates through each line of the source, counting the associated address of each line (starting at 0x200 and adding 2 after each line since one chip-8 instruction is 2 bytes), skipping every comment and label. It appends to the symbol table every label found with its associated address, which can then be used in the second pass of the assembler to replace any mention to a label with the associated address, so that in the intermediate representation of the assembler, an instruction like MOV I, .sprites becomes MOV I, 0x7AE, which is much simpler for the function that generates the actual bytecode to do its job (that instruction would simply become 0xA7AE). Of course, this also made it very easy to catch undefined and multiple-definition errors, by simply checking if the label being referenced exists in the symbol table or not, both at the parse() level and the tokenize() level.
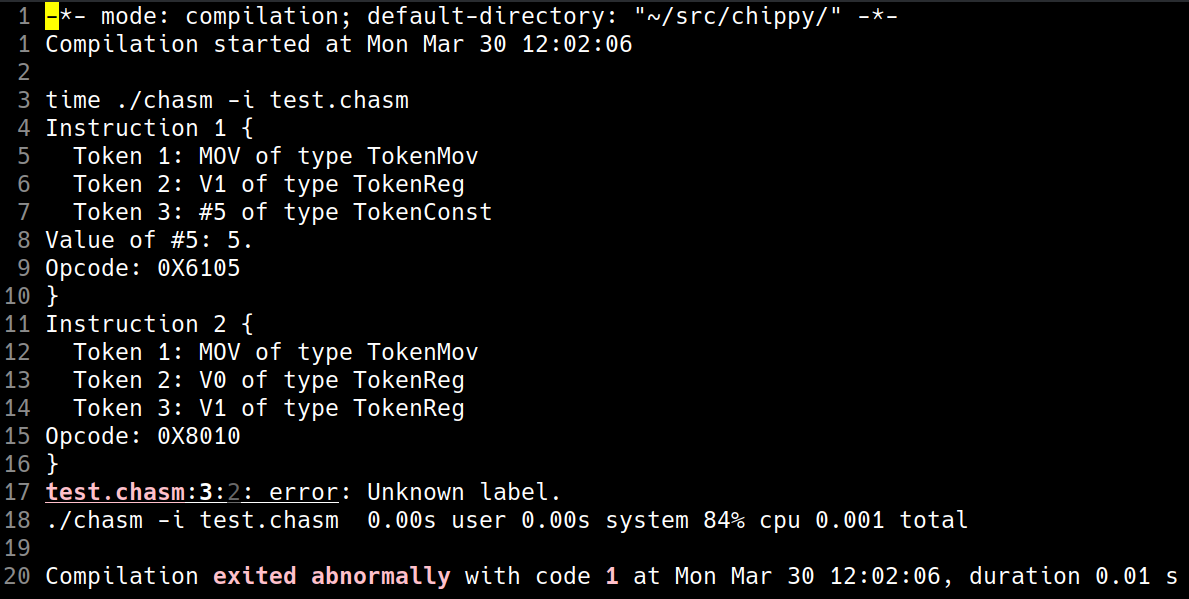
For example, this source code:
MOV V1, #5
MOV V0, V1
B .test3 ;this label doesn't exist!
.test:
.test2:
MOV V1, V3
MOV V1, #0b00100010
MOV V1, V3
RETURN
ADD V3, #0x44
would output the following:
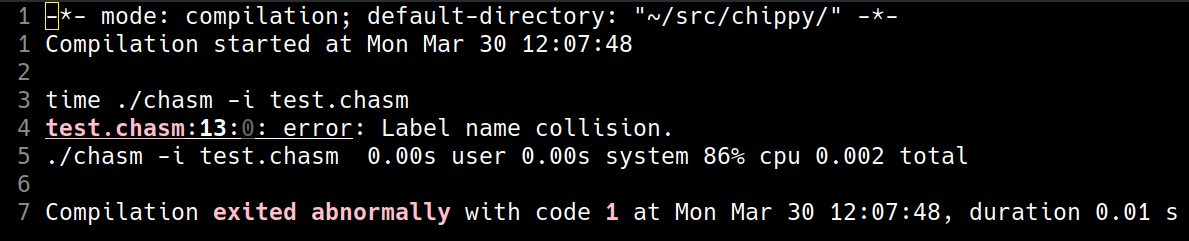
And if we change the B instruction to point to a valid label (.test2), but we instead define that label twice:
Those error messages are all in what I see be referred to as "emacs format", which is the same format GCC and other GNU utilities use when outputting errors, which integrates amazingly with Emacs (clicking on that error message takes us straight to the source file the error's at with our cursor on the exact word (token) that caused it).
Now, with a complete intermediate representation, we simply generate chip-8 bytecode from each instruction and write that directly to the ROM file (in big endian!).
To do that, we use the same data structure as chippy uses to interpret individual bits of the bytecode, but instead we write to them:
typedef union {
struct __attribute__((packed)){
uint16_t end: 4;
uint16_t y: 4;
uint16_t x: 4;
uint16_t start: 4;
};
struct __attribute__((packed)){
uint16_t address: 12;
uint16_t __pada: 4;
};
struct __attribute__((packed)){
uint16_t const8: 8;
uint16_t __padb: 8;
};
uint16_t raw;
} opcode;
With this, our previous example MOV I, .sprites can easily be translated to chip-8 bytecode:
opcode op;
op.start = 0xA;
op.address = str_to_hex(get_symb(token.data));
//get_symb() gets the associated address from the symbol table
//and str_to_hex() converts that to an integer
and now we have the 0xA7AE instruction that can easily be written to disk to finally be interpreted by chippy.
This bytecode generation is still in the works, there's a good amount of edge-cases for me to cover, but all the architecture is done. I'll then be going back to the chippy, to finally finish the emulator saga. This side-quest was a pretty long one, but it was well worth the time.
Adding syntax highlighting to this language: [Adding Color to Code]
DISCLAIMER: I know full well that there are already countless chip-8 assemblers and languages out there that I could've used. I even tried a couple on one of my streams. But considering how small the scope of the project was, I felt it would be a great exercise to make my own, especially considering how I want to make my own language(s) in the future. Also, I can now brag about having my own programming language, and although that would be a bit of a stretch, it wouldn't be a lie, so this was very much worth the time.